
The Optionality Trap: LLMs & Those Em Dashes
How models produce text and why the em dash becomes salient

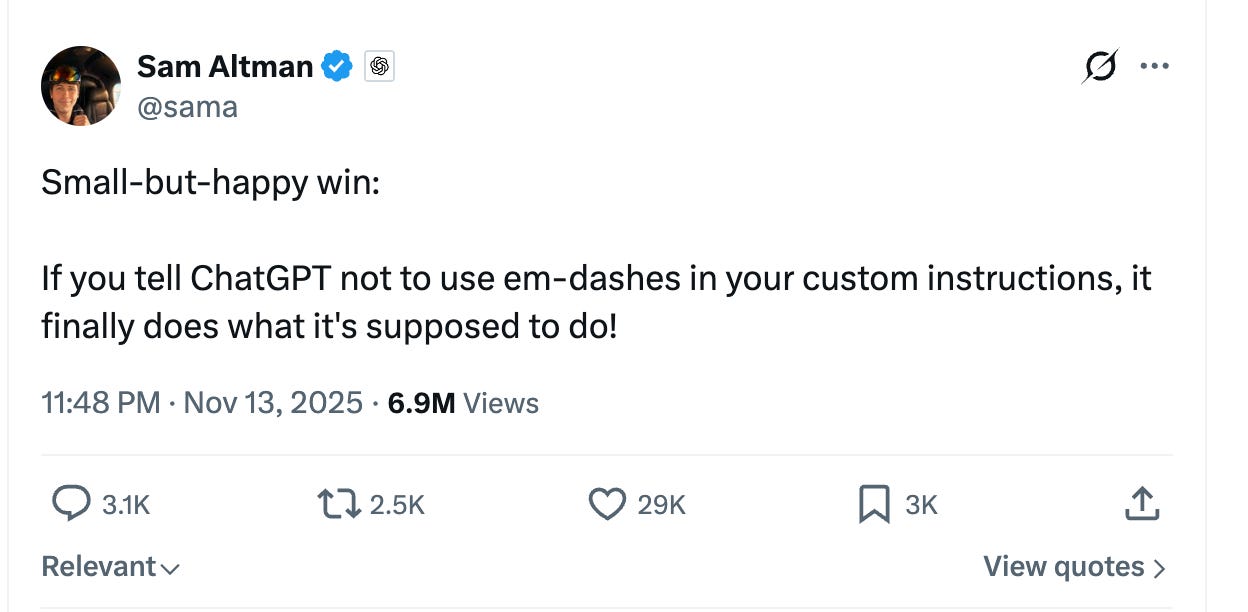
You’ve noticed
You have noticed them, the em dashes. Two per paragraph. Sometimes three. A rhythm that would not have bothered you in 2022 but now stops you mid-sentence. You may have started checking your own writing for them. You may have stopped using them entirely, worried that a colleague, an editor, a student might suspect that a machine wrote your email.
Someone will eventually scrape five years of Substack and newspaper archives and produce the scatterplot. I suspect you do not need it. You have felt it, reading prose all around you. One researcher who actually did the counting is François Keck, who pulled 10,000 English-language ecology abstracts from 2021 and 2025 and found that em-dash frequency more than doubled. No other punctuation mark moved comparably.
But why this mark, specifically?
Yesterday I was meandering around my bookshelf and picked up Amartya Sen’s Development as Freedom. The back cover carries a short paragraph describing the book. It contains two em dashes: “The role of different institutions—including the market, the state, the media, opposition groups, and non-government organizations—are seen within a broad, integrated framework.” And later: “a paradigm-altering foundation for understanding the demands of economic development—for both rich and poor—in the twenty-first century.”

The book was published in 1999. Both dashes are well placed, umm maybe not so much the second one. Still, most editors would be fine with both. And yet, reading them now, I noticed them in a way I would not have three years ago.
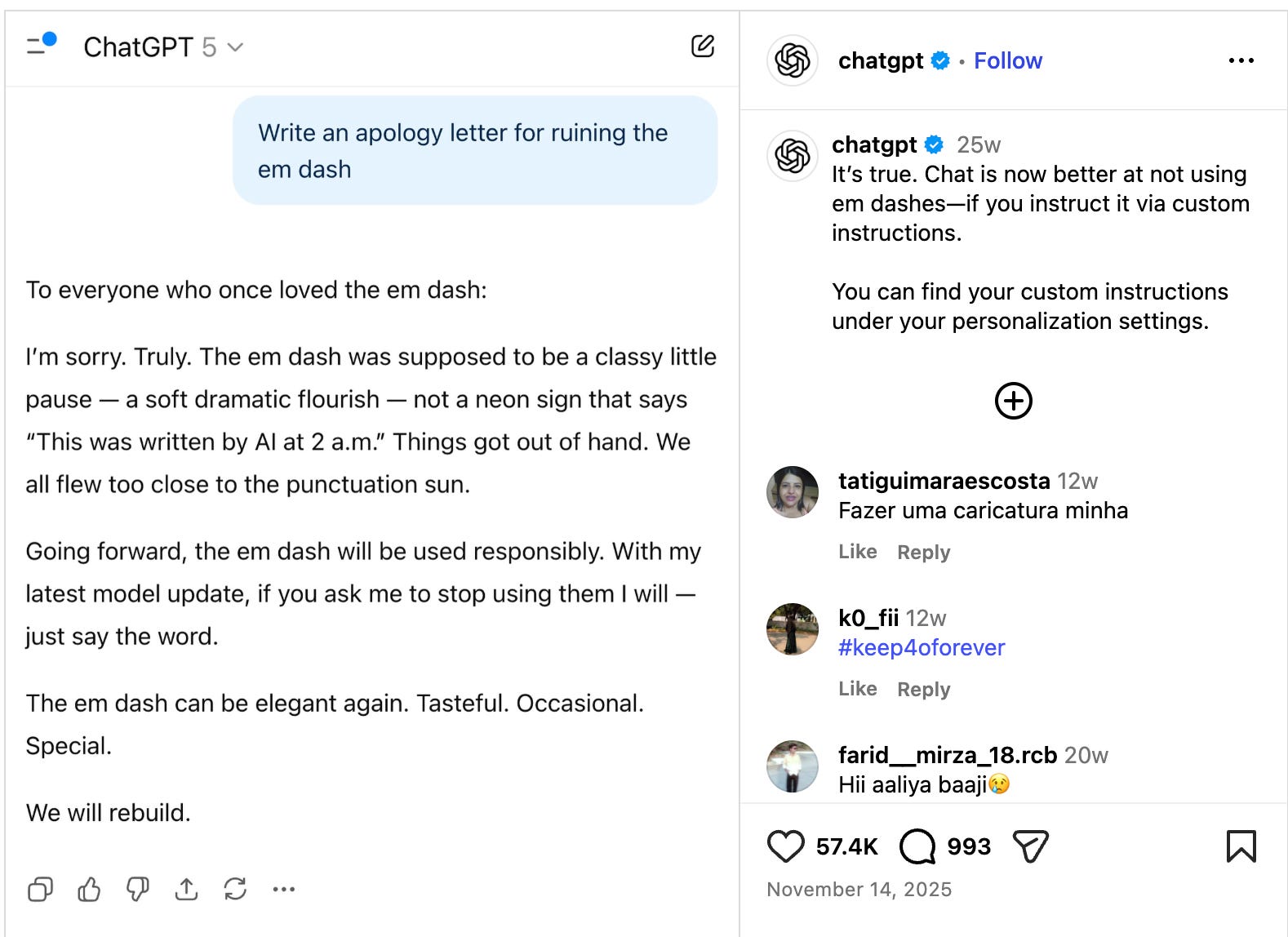
The em dash has not changed. The reader has. What changed was that large language models started producing em dashes in bulk, and we learned to hear them as a tell. Sam Altman posted on X that ChatGPT would finally obey custom instructions to avoid em dashes, calling it a “small-but-happy win.” That the fix was worth a CEO’s announcement tells you how stubborn the habit is. The punctuation mark has become a social signal: not wrong, but suspected.
The local question
Several theories have been offered for the overuse. Sean Goedecke argued that newer models were trained on digitized older books, where em-dash usage peaked. E. M. Freeburg found that markdown formatting conventions leak into prose, and that em-dash rates vary dramatically across providers: from zero in some Llama configurations to over nine per thousand words in GPT-4.1 under one suppression condition. Maria Sukhareva argued, with token-count evidence, that the em dash can be a shorter bridge between clauses: removing it often lengthens the sentence. Juzek and Ward found that ChatGPT’s famous overuse of words like “delve” is hard to explain by architecture or training data alone, and that post-training may play a role. Punctuation may have an analogous channel.
All of this is probably true, in part. And yet. When I read a paragraph with three dashes in it, the question that stays with me is not why the model likes dashes in general. It is why, at this particular spot in this particular sentence, it reached for a dash when a comma would have been better.
There is also a structural intuition, discussed in a few places, that the em dash’s flexibility gives it a natural advantage. The dash can signal so many things that a model predicting text one token at a time will reach for it by default. I think this intuition is onto something. But as it stands, it is more of a hunch than a theory. What exactly does it predict? What would count as evidence against it?
To sharpen this hunch into something testable, you have to look at what the model is actually doing at the moment it picks a punctuation mark.
One token at a time
Imagine writing on a typewriter with no backspace key. You have typed the first clause. Now you need a punctuation mark. But you have not fully worked out the second clause. Several directions feel plausible. You have to commit to the connector before you commit to what it connects to.
That is, roughly, how a large language model produces text: one token at a time, left to right, no revision. At each step, the model carries an internal state (engineers call it a hidden state) that encodes a compressed sense of what has been written and what might follow. Not a plan. More like a probability distribution over possible next moves, some weighted heavily, others lightly.
At some points in a sentence, that distribution is narrow. After “The policy has three components,” a list is coming. The colon is natural because the continuation is clear. At other points, the distribution is wide. After “The policy has been debated for years,” many things could follow: elaboration, contrast, qualification, a pivot. The continuation is not yet settled. And the punctuation mark must be chosen now.
Different punctuation marks make different promises about what follows.
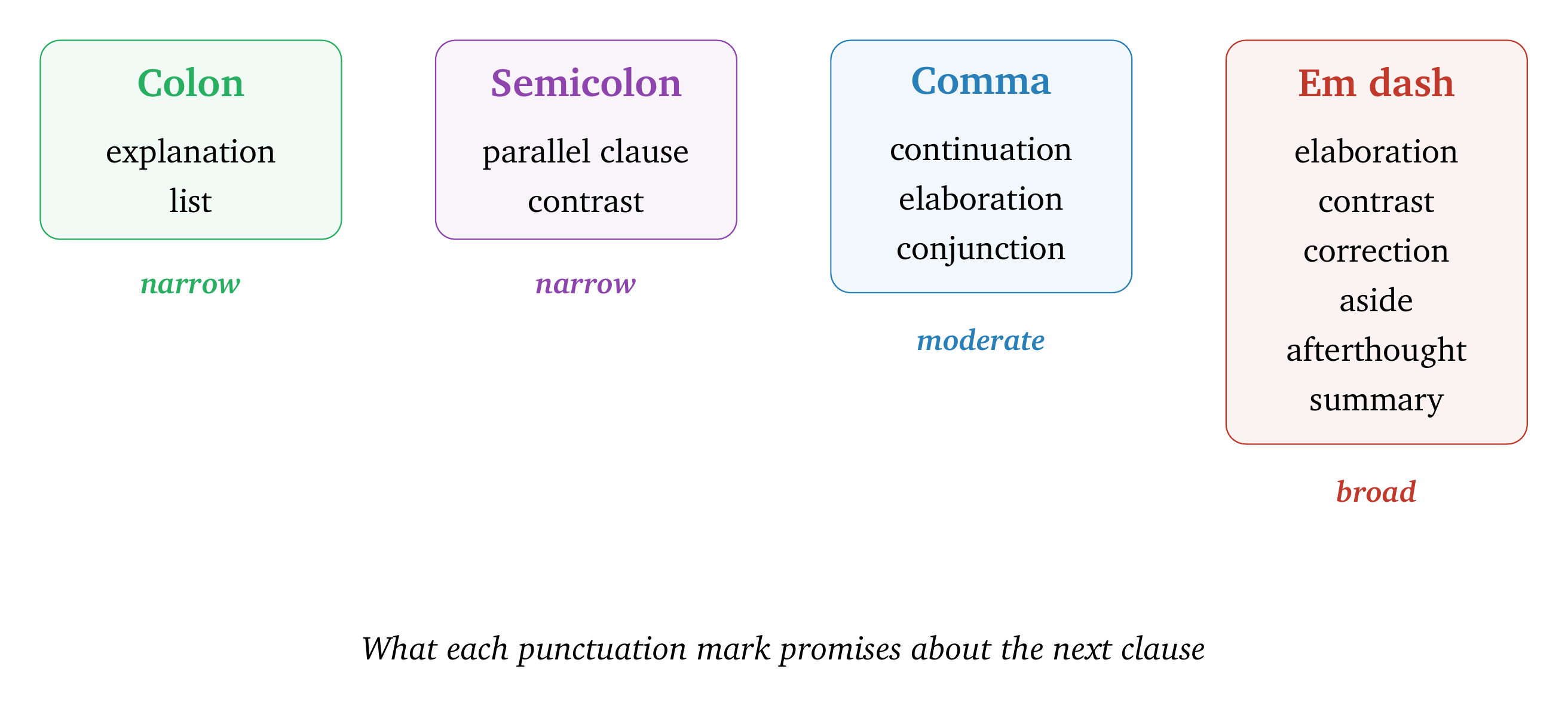
A colon promises an explanation. A semicolon promises a parallel thought. A comma promises a gentle continuation. The em dash promises almost nothing. After it, you can put a full clause, a fragment, a noun phrase, an aside, a correction. No other English punctuation mark keeps so many doors open.
So when the next move is genuinely open, the mark that works for the most possibilities wins. The em dash is that mark. I call this the optionality trap: a mark that is rarely wrong gets chosen repeatedly, and the accumulated choices produce a globally mechanical style.
Permitted is not preferred
That phrase, “rarely wrong,” is the key to the whole problem. It points to a distinction that human editors navigate every day. The model does not.
The AP Stylebook and the Guardian style guide both accept dashes. Both warn against overuse. The Guardian advises that dashes should be used sparingly. AP cautions against reaching for a dash when a comma would do. What these guides are articulating is a simple principle: permitted is not the same as preferred.
A human editor asks: what is the best mark here? She weighs meaning, rhythm, variety, house style, and whether the page already has too many dashes. A one-pass model, generating left to right without revision, asks something closer to: what mark is safe here?
Those are different questions. And the em dash wins the second one far more often than it wins the first.
The model does not sprinkle extra dashes onto otherwise normal prose. It replaces more specific punctuation with the all-purpose connector. Try it yourself. Look at any AI-generated paragraph with multiple dashes and ask: what would a human editor have used instead?

In each pair, the dash is fine. But the comma, the colon, the parentheses are better. That is what the collapse of the permitted/preferred distinction looks like in practice.
This is where Sen comes back. The dashes on the back cover of Development as Freedom are there because someone (perhaps the editor) decided they belonged. Arguably, the model’s em dashes are there because nothing ruled them out. The difference is invisible at the level of any single sentence. It is unmistakable at the level of a page.
This is a theory, not yet a tested claim. But it makes a specific prediction: the model’s excess over human punctuation choices should be largest exactly where the continuation is most open, where many next moves are plausible and the dash keeps the most doors ajar. If that prediction fails, the theory is wrong. If it holds, we have something useful: a precise account of why a model makes one local choice rather than another. That is a piece, small but tractable, of the much larger problem of understanding what these systems are actually doing when they produce text.
Collateral damage
But the mechanism is not the whole story. There are also consequences, and they cut both ways.
Mandel and Imas show that people devalue creative work when they believe AI was involved, even when they cannot tell it apart from human work. The em dash is at risk of becoming that kind of marker: a stylistic feature that signals origin rather than quality. Some writers appear to be avoiding it; others, reading AI-assisted prose daily, seem to be picking it up without noticing. Sen’s dashes, written a quarter-century before ChatGPT, are collateral damage.
There may also be a mechanical reason why the problem compounds. The model conditions on its own output: once an em dash appears, the stylistic signal it carries plausibly makes subsequent dashes more probable. If so, the style locks in within a single passage. This is why AI prose does not just have more dashes. It has clusters of them.
And the pattern should not be specific to English. If the mechanism is right, we should expect it to surface differently across languages: each writing system most vulnerable around its own flexible, low-commitment connectors. In Korean, comma patterns are already a detectable signal of AI-generated text. In Hindi, which does not conventionally use the em dash, the overproduction should shift to a different device entirely. The em dash is the English case, not the universal object.
A locally safe choice, repeated many times without editorial restraint, becomes a visible style signature. That signature is now reshaping how we read, how we write, and how we judge each other’s writing.
The em dash is a small test case for two problems we have not yet solved: understanding why models produce what they produce, and knowing when to trust them. The first is a prerequisite for the second. The em dash sits exactly at the boundary where convenience and craft diverge. It is not the disease. It is the most legible symptom. And the first step toward a cure is understanding why the model reaches for it: not because it is best, but because it is so rarely wrong.
Interesting hypothesis! One additional observation: when Shakespeare wrote his plays, the use of em-dashes were extremely rare if not absent. However most modern editions of his plays use em-dashes extensively.
One likely reason is the different cognitive pathways our brian choose while producing original work vs. when we are reproducing something. The latter could involve more analytical stages. For instance, someone editing Shakespeare's work today needs to ensure that Shakespeare would indeed write something like that or if it adheres to his writing style. This requires not only knowledge of a large body of Shakespeare's work but also familiarity with his style. In other words, the editor is not only editing the work but simultaneously using his knowledge of Shakespeare's literary style to self-correct.
AI is a bit like this, I suspect, because a large chunk of the tasks most people assign to them are analytical/research/summaries/math/graphs, etc. Here the pathway is not much of original creative writing but one of reproducing something. Constantly embarking itself along such analytical pathways could have likely skewed the LLM’s thinking process because LLMs use em-dashes in equal generosity while writing fiction work too.
Perhaps, a bit of Shakespeare is what we all need
Incredible read! I literally just wrote the other day about how I’m so acutely aware of the em dash. It’s interesting to read about the differences in general grammar em dash and why LLM models use it aggressively.